Does ARC Measure Intelligence?
What’s ARC?
ARC (Abstraction and Reasoning Corpus) is an intelligence benchmark, that now has a $1.1m prize attached to it. It’s made by Google engineer François Chollet and it’s meant to be easy for humans, and hard for machines. You can claim the prize by submitting an open source model to the ARC Prize for evaluation. They’ll test it against a private test suite, and if it can outperform humans (85% in the benchmark, machine SOTA is currently 35%) you win $500,000 (the rest of the $1.1m is made up of prizes for other ARC milestones and competitions).
Let’s look at some example problems:

I think it’s fair to say these are quite easy for humans, apparently 5 year olds do well at them (though I should admit here that I screwed up the second question in the playground by baselessly assuming all grids were square, and then flailing around for a while trying to work out what I was doing wrong—very embarrassing).
Despite this, frontier models (Claude 2, GPT-4, Gemini Ultra) do terribly at ARC. I think I have a reasonably good intution for what tasks good LLMs can and can’t do well, but the fact they can’t do this really broke my model.
Chollet, and Mike Knoop (co-founder of Zapier, and funder of the ARC Prize) did an interview with Dwarkesh Patel on the ARC Prize. Chollet claims his benchmark is a good measure of fluid intelligence. Modern LLMs are apparently stumped by it because they don’t really have fluid intelligence, only a sort of advanced pattern matching, gluing together concepts they learn from training data to give plausible-looking answers.
Why do I have a problem with it?
Chollet doesn’t claim ARC is perfect, and because it’s imperfect, he thinks someone could “cheat” by generating a large number of example ARC problems, and training a model on them until it learns the gist of the patterns involved, and is able to solve test problems by means he deems unintelligent.
But I’m not convinced this isn’t what humans are doing to solve these problems. These tests were designed to be easy for humans, and as a result, I think they end up looking a lot like “data” we were trained on in our ancestral environment. Here are some examples of what I mean…
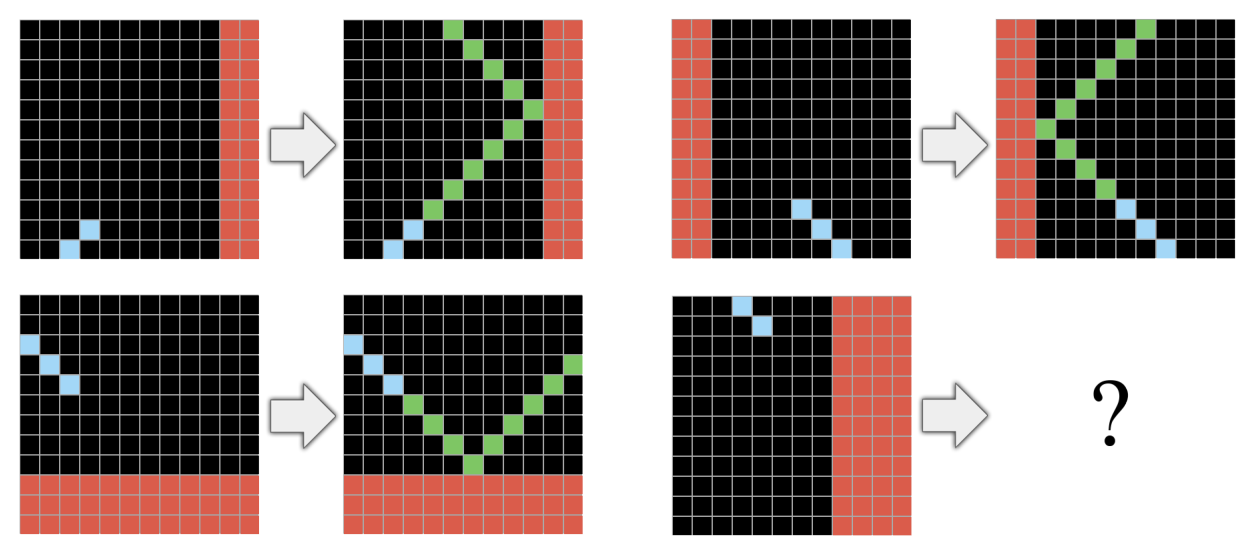
This one looks like a rigid body collision on a 2D plane, or more simply, it looks like the sort of path a billiard ball would take. Humans (and most animals) have had to evolve a rough model of Newtonian mechanics to survive, and this is a Newtonian mechanics sort of problem.
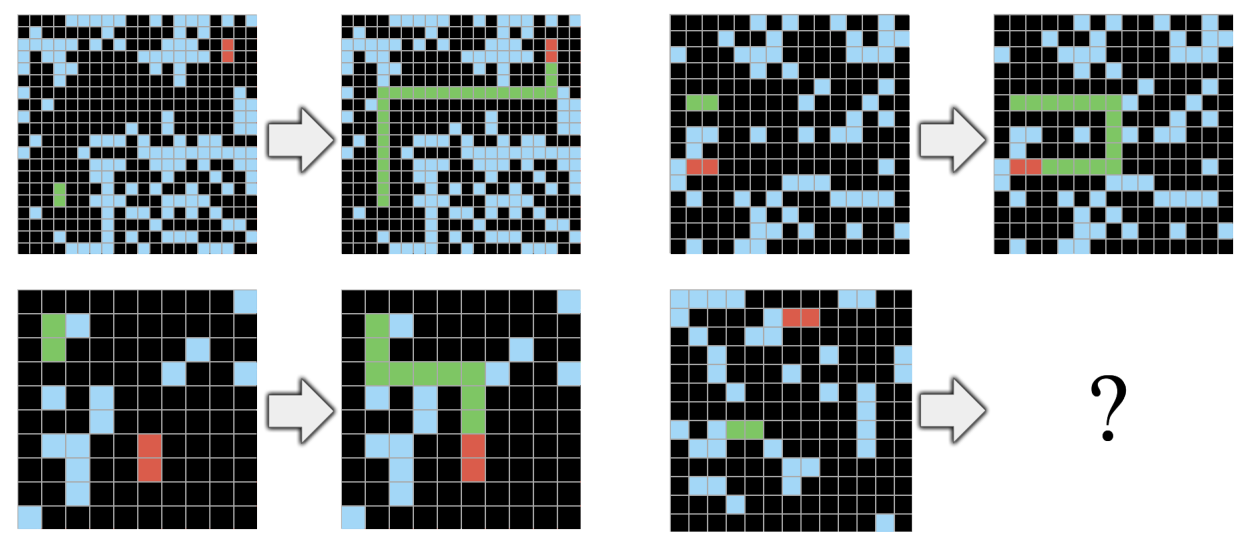
Here’s a denoising problem:
This is the sort of thing humans do subconsciously. We (at a distance at least) see the world as a flat plane, and shapes we want to resolve are often partially obscured by “noise”. Noise like leaves, rain, or clouds of flies.
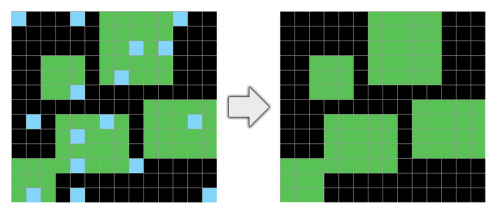
If you squint, this one looks like rock pools filling with water as the tide goes out. More generally, it’s about spotting enclosed spaces. That’s the sort of thing that can be useful for making pottery that holds water as opposed to leaky pottery with holes in it. Or it could come in handy for deciding how to not corner yourself when you’re being chased by a predator. Alright, one more:

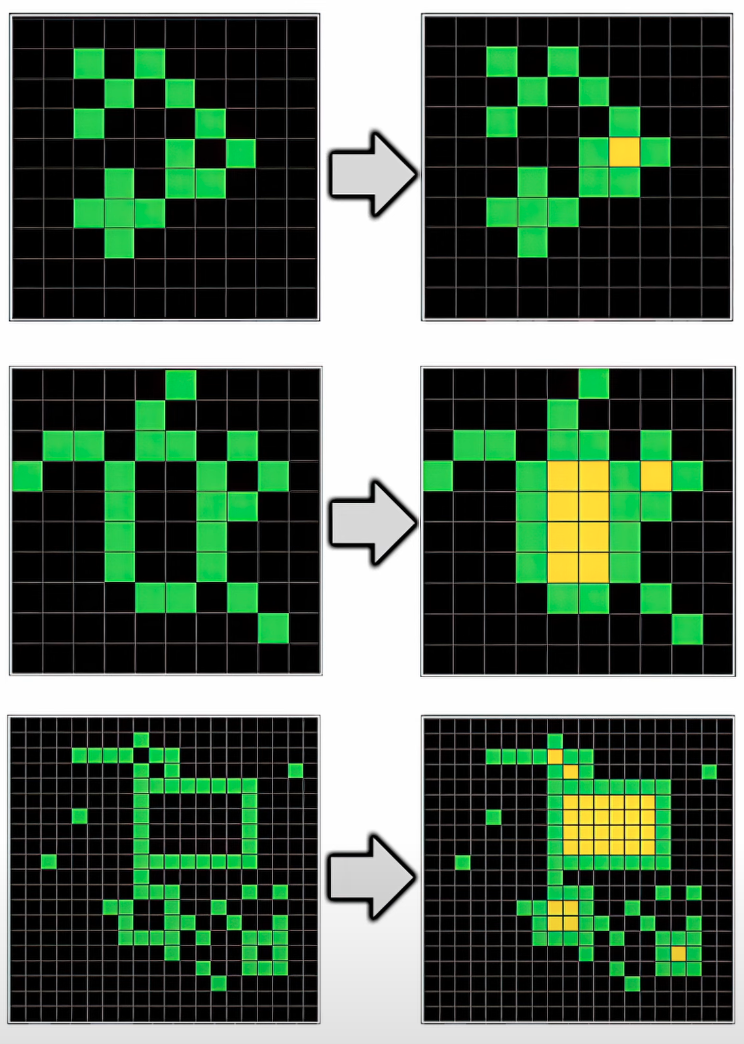
This is a symmetry problem in a 2D plane. Humans are good at symmetry, it might not be immediately obvious why, but I think I have a semi-plausible story that could be representative of the sort of stories that lead us to being good at symmetry. Imagine you’re a caveman in the human ancestral environment, you makes a living knapping, and using, flint hand axes. You don’t want an asymmetric hand axe, it might throw your strike off balance and injure your wrist, it might make the other cavemen laugh at you, it might give cavewomen the ick. So selection pressure might have given us a keen eye for symmetry.
This selection pressure means that, to give a human an eye for 2D and 3D symmetry, you have to raise them in a somewhat normal-for-humans environment. To give a human an eye for D > 3 symmetry, you have to teach them to read, hope they’re smart, teach them basic maths, give them a textbook on symmetry, and they still won’t find it intuitive. No one thinks this means humans aren’t generally intelligent, there are just some problems evolution has trained us for, and some problems we have to grind out by using advanced pattern matching, gluing together concepts we’ve learnt from our training data ancestral environment.
So is this what’s happening to LLMs when they’re faced with this problem? I think it might be. LLMs are trained on large corpora of text, they have some intuition for matrices of text that seems to suggest they can pick up on 2D patterns. But I don’t think it’s their bread and butter. Likewise, multi-modal models, as far as I’m aware (and I’m not that aware of the cutting edge in open source, let alone the secret stuff) work by training on a corpus of text, and then fine tuning them for vision in tandem with a “vision endoder” that gives the main model a description of the image. I wouldn’t expect this process to produce something that’s natively “at home” with vision problems. Though, to be honest, I’m pretty out of my depth here, and I could well be wrong.
More anecdotally, when GPT-4V was first launched, it came with a disclaimer that the model could see the contents of an image, but would often get confused about where things were in relation to other things. Clearly we’d expect anything that can’t reason about spatial relationships to fall flat on its face attempting ARC.
As with higher-dimensional symmetry problems, we can imagine another easy-for-machines-hard-for-humans ARC by considering AlphaFold-3-like models that are trained on protein and DNA data. I say AlphaFold-3-like because I’m not very familliar with the limitations of AlphaFold 3, so I can’t be sure it’s capable fo solving the problem I’m about ot propose, but it seems very likely that there’s some AlphaFold N for which this problem is trivial. So what would a trivial ARC problem for a biological ML system look like? I propose it would look like this:
[DNA snippet that codes for simple protein A with left-handed chirality] -> [DNA snippet that codes for right-handed version of protein A]
[DNA snippet that codes for simple protein B with left-handed chirality] -> [DNA snippet that codes for right-handed version of protein B]
[DNA snippet that codes for simple protein C with left-handed chirality] -> ?
A suitably advance protein-folding model will laugh in the face of this problem, and I’m sure there are many other problems for which that is the case, but unfortunately I’m already at the limit of my molecular biology knowledge, so I can’t imagine what they are. For a human, fresh out of the ancestral environment, to solve this they’ll need to try techniques like: getting out a pen and paper, talking to other humans, publishing papers, creating research insitutes, creating an advanced society capable of producing advanced technology for the research institutes… You get the idea. LLMs can’t do these sorts of things to tackle problems they don’t find intuitive yet, but that’s not news, everyone agrees that’s a limitation they have! ARC throws that limitation into unintuitive relief, but I’m not convinced it’s telling us anything more than that the overlap between what humans find intutive and what LLMs find intuitive is weird.
If LLMs struggle with ARC problems because they’re in the wrong domain, can they pass them when when they’re translated into a domain they’re at home with? I think so, take the counting problem:
The ARC paper describes this as
A task where the implicit goal is to count unique objects and select the object that appears the most times
Here’s my first attempt at translating that into a text problem and feeding it into GPT-4o
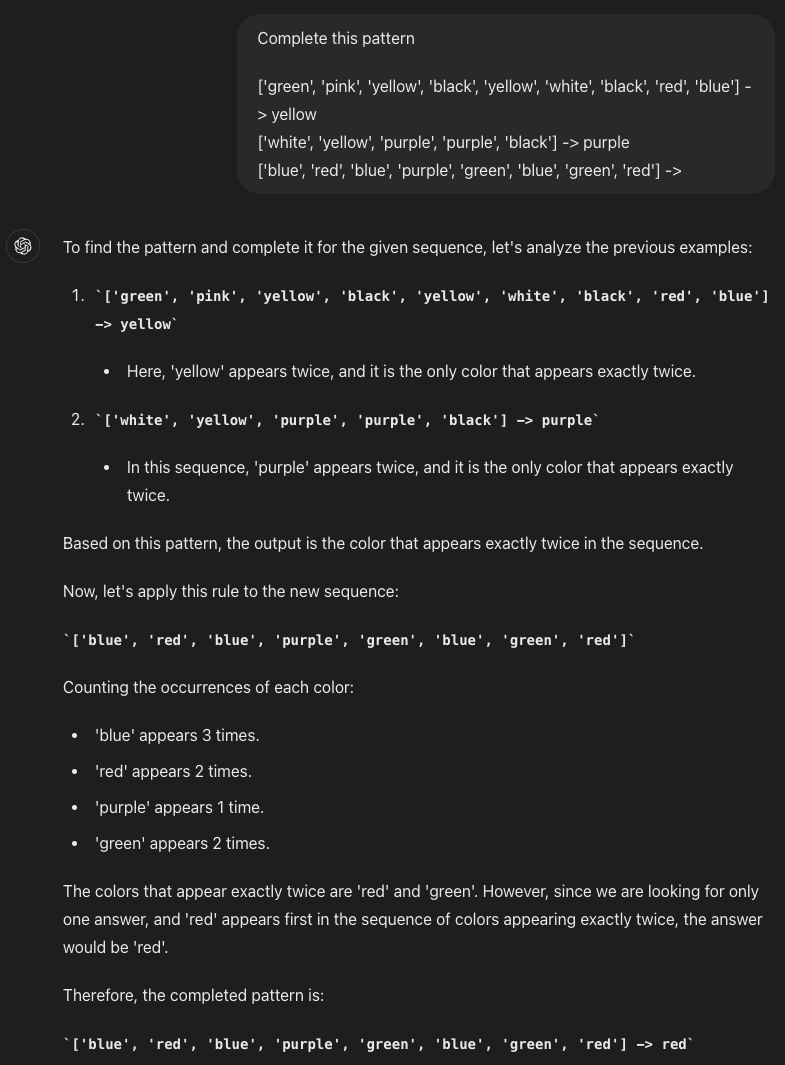
Not the answer I wanted, but that’s my fault. The examples I gave happened to have two valid solutions, and ChatGPT picked the one I didn’t have in mind. Let’s try again:

That’s a pass. I’d be very surprised if this sort of reasoning test wasn’t in GPT-4’s training data, so in a way we’re not learning much, it’s probably just copying a template it learnt in training. But this could have failed, and it didn’t. I think you’re meant to call that Bayesian evidence. On the other hand, most humans have also come across tests like this in their lifetime, and sort of get the gist of what they’re meant to do, even without instructions or context. I don’t think it’s clear that, if you plucked a person from North Sentinel Island, they’d actually do particularly well without implicit concepts of things like tests, and maybe even pixels.
If my model for what’s going on with ARC is correct, it looks like there are two ways we can get current ML techniques to perform well. We can either train them to have more human-like intuitions, which Chollet thinks is cheating; or we can train them to be more agentic, grinding out unintutive problems like humans working in research institutes. But everyone—even the LLM boosters—agrees this is a thing LLMs need to get better at before they can be called generally intelligent. It also wouldn’t surprise me if human-like intuitions, agency, or both, fall out of scaling up frontier LLMs.
What’s the case against my case against?
The case against my model is that ARC has been around for almost five years now, and no one’s beaten it. If it were possible to beat it by making relatively minor changes to existing approaches, surely someone would have done it by now? But then, it’s a benchmark that’s remained relatively obscure (Chollet thinks this is because of a sort of publication bias, where a benchmark is neglected until someone starts to get traction on it) and that’s why this prize is so interesting. It looks as if it will bring enough attention to ARC that low-hanging fruit is bound to be picked.
The ARC Prize website has this chart of benchmark progress:
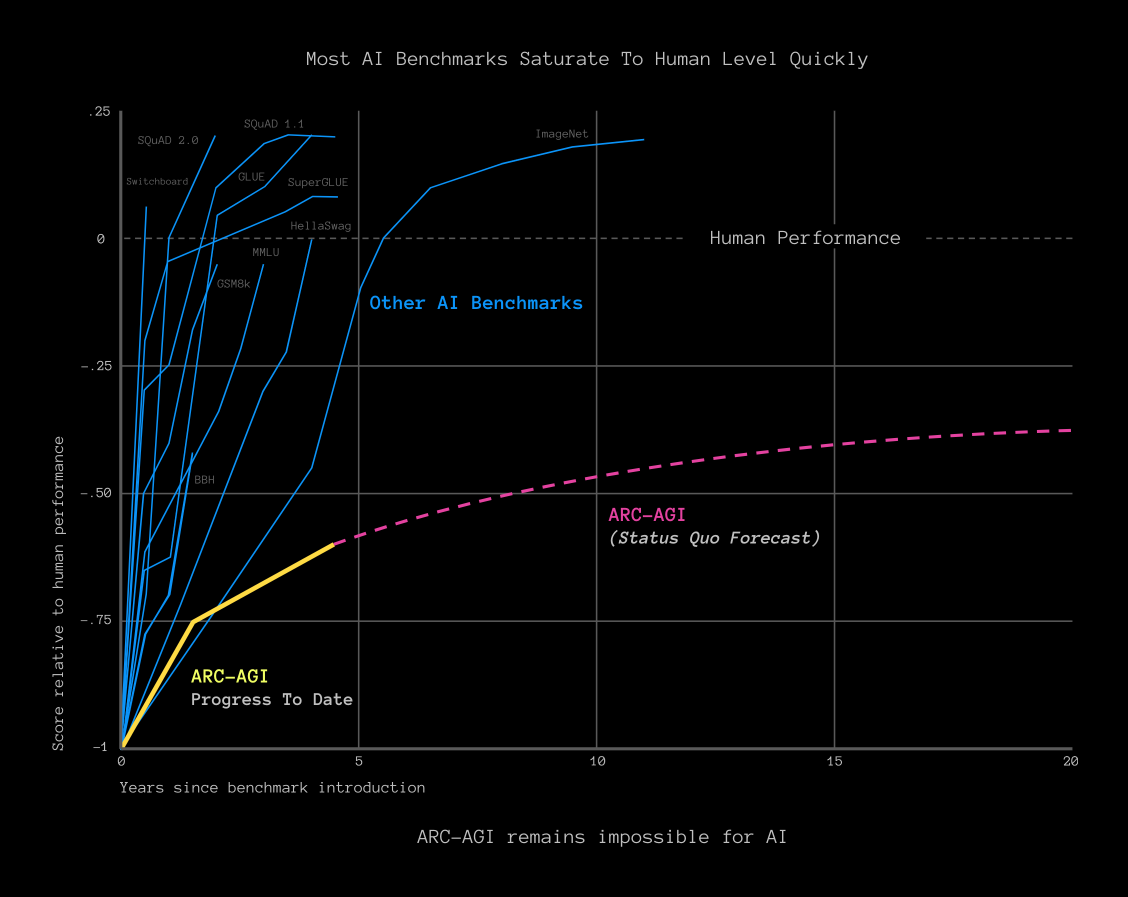
If it were my $1m on the line, this would make me nervous. To me the ARC trend looks a lot like all the others, with the x-axis stretched out a bit, and the forecast looks like a complete guess. The progress so far looks entirely consistent with more scale crushing this benchmark, especially since the joint best-performing model was an LLM with 240m parameters. That’s about 3 orders of magnitude less than what frontier models are rumoured to have. So there’s reason to think that an ARC-focused LLM, with more scale, could do much better.
As far as I can tell, and I may be wrong about this, there’s no rule to stop someone winning this competition by generating a tonne of synthetic tests, and training on them, i.e. using a method the creators think of as cheating. So my default guess is that the ARC Prize gets claimed within 3 years, by someone who’s using an approach the creators aren’t happy with. It feels about 50% likely to me that the next generation of LLMs matches or exceeds human performance, and if the generation after that doesn’t, then I think I’ll start to consider it more likely than not that this post got something badly wrong.